交叉连接与集合
目前我们所有的实验工作,基本都围绕着单张数据表而进行,然而��,在实际的生产环境之中,业务更多时候需要依托多张数据表的工作,这就需要我们执行一种名为“连接”的操作。
假定在 AtomGit 上面,存在有下面两张数据表,users 表(用于记录所有的用户)与 issues(用于记录在某个仓库中分配给用户的 Issue):
/* 数据表的内容经过简化 */
CREATE TABLE users (
user_id INTEGER, /* 用户 ID */
name TEXT /* 用户名称 */
);
CREATE TABLE issues (
user_id INTEGER, /* 该 Issue 被分配给的用户 */
issue_title TEXT/* Issue 的标题 */
);
初始数据如下:
/* users */
INSERT INTO users VALUES (1, 'Wen Yi');
INSERT INTO users VALUES (2, 'Li Xiao Ming');
INSERT INTO users VALUES (3, 'Zhang Fei');
INSERT INTO users VALUES (4, 'Liu Shi De');
/* issues */
INSERT INTO issues VALUES (NULL, '建议 AtomGit 支持用户投稿功能');
INSERT INTO issues VALUES (1, '建议 AtomGit 加快支持全文搜索');
INSERT INTO issues VALUES (2, '建议完善 PR 有关文档');
INSERT INTO issues VALUES (3, '建议 AtomGit 支持 svg 格式图片');
INSERT INTO issues VALUES (4, '解决 Pages 乱码问题');
INSERT INTO issues VALUES (2, '建议社区讨论面向外部开放');
INSERT INTO issues VALUES (4, '希望尽早推出 AtomGit 移动端');
之后,我们将结合具体的业务场景,分析连接操作的应用。
内连接(Inner Join)
内连接是一种应用非常普遍的连接操作,它的基本形式如下所示:
SELECT /* 最终返回的数据列 */ FROM /* 左表 */ INNER JOIN /* 右表 */ ON /* 连接的条件 */;
左表与右表是形式上摆放位置的左右次序而形成的一种习惯性称呼。
而它整合数据表的思路也非常简单:内连接(Inner Join)只要符合 ON 后面所列明的条件,就可以进行整合。
比如,下面的查询根据 issue 所对应的 user_id 同用户表中的 user_id 进行匹配:
SELECT users.user_id, name, issue_title FROM users INNER JOIN issues ON users.user_id = issues.user_id;
对于多张数据表中出现的重名数据列,通过 table_name.column_name 这种方式,可以实现区分。

可以注意到,一条并没有任何对应 user_id 的 issue 并没有被整合进入到最终的结果数据表之中。

(Inner-Join 的结果将会是符合条件的部分,倘若全部记录符合条件,左右表组合的全部记录将会返回)
左连接(Left Join)
左连接的基本形式与内连接有所不同,参考如下:
SELECT /* 最终返回的数据列 */ FROM /* 左表 */ LEFT JOIN /* 右表 */ ON /* 连接的条件 */;
而它构建返回结果的方式,自然也有所不同:
- 对于左数据表的全部记录,无条件全部予以返回
- 对于右数据库的记录,选择符合
On Contidion的部分予以返回
假若我们希望搜集得到所有的用户与他们所分配到的 Issue,则可以使用如下的查询语句:
SELECT users.user_id, name, issue_title FROM users LEFT JOIN issues ON users.user_id = issues.user_id;

可以发现,这一次返回的结果,似乎同先前内连接的结果没有什么不一样,这是因为我们所有的用户,都有着与之分配的 Issue,尝试加入一条全新的用户记录,即可得到一个不一样的结果:
INSERT INTO users VALUES (5, 'Wu Guang Zhong');
/* 再次选择 */
SELECT users.user_id, name, issue_title FROM users LEFT JOIN issues ON users.user_id = issues.user_id;
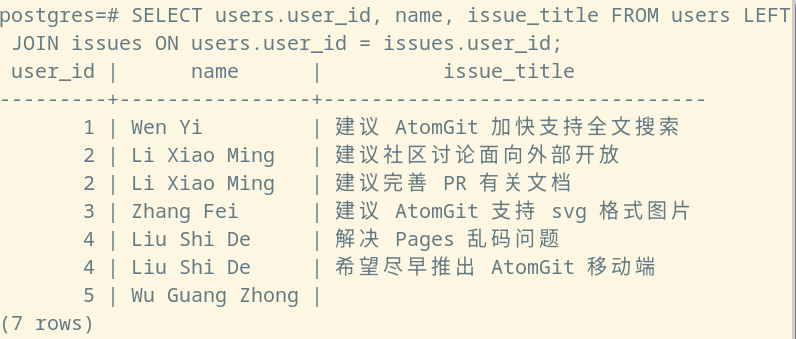
对于一张数据表中存在,而另外一张数据表中不存在,且匹配条件在全体数据列为部分满足(或全部不满足)的时候,不匹配但是组合的数据条目将会留空。

左连接同时被称为“左外连接“(Left outer join)。
右连接(Right Join)
右连接与左连接的区别在于,右连接会将右部数据表的数据记录全部返回,同时返回左部数据表中与之匹配的部分。
基本形式如下所示:
SELECT /* 最终返回的数据列 */ FROM /* 左表 */ RIGHT JOIN /* 右表 */ ON /* 连接的条件 */;
假如我们希望查询所有 Issue 所对应的用户,则可以书写如下的查询语句:
SELECT users.user_id, name, issue_title FROM users RIGHT JOIN issues ON users.user_id = issues.user_id;

可以发现,这一次留空的对象,变成了作为左表而设立的用户表。

右连接同时被称为“右外连接“(Right outer join)。
全连接(Full Join)
全连接非常适合于完全整合两张数据表,它的策略是:如果符合 On Condition 的条件,则按数据属性完全填充整合后的各个数据项,否则留空。
基本形式如下所示:
SELECT /* 最终返回的数据列 */ FROM /* 左表 */ FULL JOIN /* 右表 */ ON /* 连接的条件 */;
我们继续沿用刚才的匹配条件,则一张直观地展现匹配情况的数据表,将会被构造给我们:
SELECT users.user_id, name, issue_title FROM users FULL JOIN issues ON users.user_id = issues.user_id;
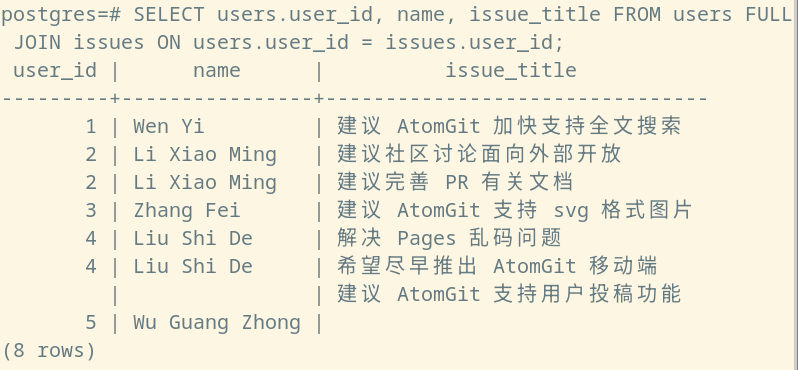

全连接同时被称为“全外连接“(Full outer join)。
交叉连接(Cross Join)
交叉连接又被称作“笛卡尔积”,它是要连接的数据表的数据列的全排列。
继续沿用上述全连接的查询语句,只不过这一次,我们将 On Condition 所对应的条件设置为全部为真:
SELECT users.user_id, name, issue_title FROM users FULL JOIN issues ON TRUE;

可以发现,这一次返回的数据条目增加了许多,他们便是全排列(罗列出各数据项组合的全部可能性)所得出来的结果。